{kind=link}
Wide-Baseline Segment Matching (ScanNet++)
Reference image pairs and SegMASt3R matches demonstrating robustness to 180° viewpoint changes and perceptual aliasing. Colors indicate matched segments; correct matches are contiguous across views.
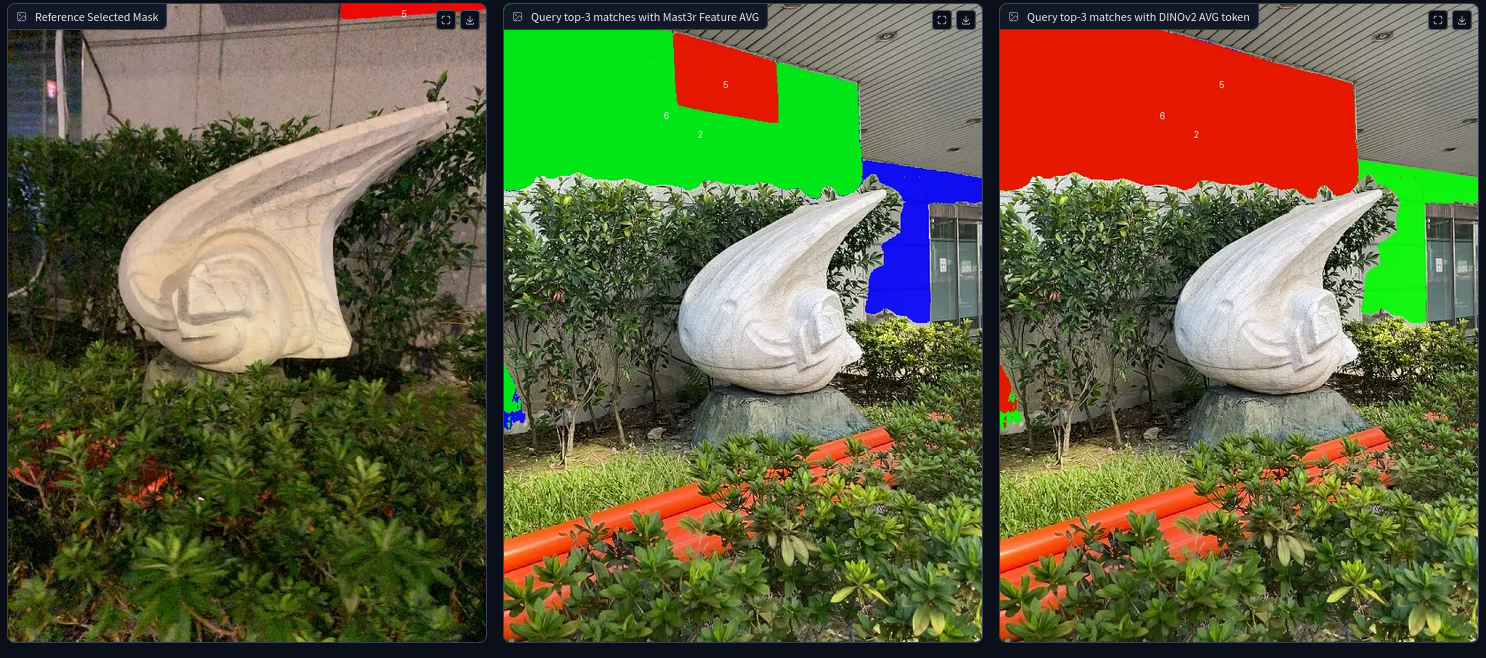



Segment matching is an important intermediate task in computer vision that establishes correspondences between semantically or geometrically coherent regions across images. Unlike keypoint matching, which focuses on localized features, segment matching captures structured regions, offering greater robustness to occlusions, lighting variations, and viewpoint changes. In this paper, we leverage the spatial understanding of 3D foundation models to tackle wide-baseline segment matching, a challenging setting involving extreme viewpoint shifts. We propose an architecture that uses the inductive bias of these 3D foundation models to match segments across image pairs with up to 180° rotation. Extensive experiments show that our approach outperforms state-of-the-art methods, including the SAM2 video propagator and local feature matching methods, by up to 30% on the AUPRC metric, on ScanNet++ and Replica datasets. We further demonstrate benefits of the proposed model on relevant downstream tasks, including 3D instance segmentation and object-relative navigation.

Pipeline Overview: A wide-baseline image pair is processed by a frozen MASt3R backbone to extract patch-level features; masks from a parallel segmentation module or ground truth masks and these patch-level features are aggregated by the segment-feature head to form per-segment descriptors, which are then matched across images via a differentiable optimal-transport layer to produce the final matched segments.
| Method | 0°–45° | 45°–90° | 90°–135° | 135°–180° | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUPRC | R@1 | R@5 | AUPRC | R@1 | R@5 | AUPRC | R@1 | R@5 | AUPRC | R@1 | R@5 | |
| Local Feature Matching | ||||||||||||
| SP-LG | 42.1 | 45.6 | 51.2 | 33.5 | 36.9 | 43.1 | 15.9 | 19.7 | 26.2 | 6.1 | 9.3 | 14.6 |
| GiM-DKM | 59.1 | 64.9 | 69.7 | 54.9 | 60.2 | 66.1 | 39.6 | 44.5 | 51.8 | 21.3 | 25.9 | 32.7 |
| RoMA | 61.6 | 68.7 | 73.5 | 58.9 | 66.4 | 73.0 | 47.4 | 56.1 | 65.5 | 30.0 | 39.5 | 49.7 |
| MASt3R (LFM) | 59.5 | 68.3 | 74.2 | 57.3 | 65.6 | 72.5 | 52.9 | 60.3 | 68.9 | 45.4 | 52.6 | 62.2 |
| Segment Matching | ||||||||||||
| SAM2 | 61.9 | 64.6 | 67.5 | 46.6 | 50.1 | 54.0 | 27.9 | 32.5 | 37.2 | 17.0 | 21.6 | 25.4 |
| DINOv2 | 57.9 | 66.7 | 87.4 | 43.0 | 55.9 | 83.2 | 33.5 | 48.0 | 78.0 | 32.4 | 46.0 | 75.6 |
| SegVLAD | 44.2 | 58.6 | 81.4 | 32.1 | 49.5 | 76.5 | 23.2 | 42.2 | 70.5 | 20.0 | 39.6 | 66.8 |
| MASt3R (SegMatch) | 51.7 | 54.6 | 69.9 | 45.6 | 49.8 | 68.5 | 41.4 | 47.9 | 69.2 | 39.5 | 48.7 | 72.6 |
| SegMASt3R (Ours) | 92.8 | 93.6 | 98.0 | 91.1 | 92.2 | 97.6 | 88.0 | 89.5 | 96.8 | 83.6 | 85.9 | 95.9 |
SegMASt3R improves AUPRC and recall across all pose-bins on ScanNet++.
| Method | 0°–45° | 45°–90° | 90°–135° | 135°–180° | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUPRC | R@1 | R@5 | AUPRC | R@1 | R@5 | AUPRC | R@1 | R@5 | AUPRC | R@1 | R@5 | |
| Local Feature Matching | ||||||||||||
| MASt3R (LFM) | 78.2 | 86.5 | 89.4 | 69.5 | 77.6 | 81.0 | 48.0 | 60.4 | 64.6 | 32.5 | 49.0 | 54.1 |
| Segment Matching | ||||||||||||
| MASt3R (SegMatch) | 52.2 | 57.5 | 81.2 | 39.1 | 51.0 | 78.6 | 23.6 | 45.9 | 77.2 | 17.2 | 43.8 | 75.7 |
| SAM2 | 80.09 | 82.28 | 84.61 | 54.58 | 62.03 | 65.41 | 40.69 | 53.72 | 56.67 | 37.78 | 54.59 | 56.42 |
| DINOv2 | 55.85 | 74.25 | 96.55 | 31.12 | 59.64 | 92.84 | 21.71 | 57.68 | 92.33 | 17.29 | 59.28 | 89.64 |
| SegMASt3R (Ours) | 95.0 | 96.0 | 98.6 | 86.2 | 91.2 | 96.4 | 73.4 | 85.2 | 95.7 | 68.4 | 83.8 | 94.8 |
SegMASt3R maintains high AUPRC and recall across pose-bins under distribution shift.
| Method | 0°–45° | 45°–90° | 90°–135° | 135°–180° | Overall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUPRC | R@1 | R@5 | AUPRC | R@1 | R@5 | AUPRC | R@1 | R@5 | AUPRC | R@1 | R@5 | AUPRC | R@1 | R@5 | |
| SAM2 (Video Prop) | 63.89 | 75.16 | 76.81 | 50.29 | 58.84 | 61.5 | 31.42 | 38.23 | 41.75 | 20.19 | 25.93 | 28.75 | 41.47 | 49.56 | 52.22 |
| MASt3R | 34.37 | 40.14 | 52.03 | 28.62 | 34.43 | 45.75 | 24.72 | 30.67 | 42.42 | 23.70 | 29.74 | 42.20 | 27.86 | 33.75 | 45.60 |
| DINOv2 | 39.20 | 45.63 | 61.09 | 25.96 | 32.96 | 48.83 | 19.91 | 27.01 | 41.73 | 17.37 | 24.55 | 37.84 | 25.62 | 32.54 | 47.38 |
| SegMASt3R (AMG / FastSAM) | 70.89 | 74.43 | 76.94 | 68.25 | 72.05 | 74.55 | 64.44 | 68.83 | 71.78 | 60.32 | 65.48 | 68.27 | 65.98 | 70.20 | 72.89 |
Even with noisy masks from FastSAM / SAM2, SegMASt3R maintains high precision and recall.
| Method | Train Dataset | Eval Dataset | Overall | 0°-45° | 45°-90° | 90°-135° | 135°-180° |
|---|---|---|---|---|---|---|---|
| DINOv2 (off-the-shelf) | Multiple | MapFree | 84.4 | 85.4 | 85.2 | 83.5 | 83.8 |
| MASt3R (Vanilla) | Multiple | MapFree | 69.2 | 73.4 | 69.8 | 70.0 | 66.1 |
| SegMASt3R (SPP) | ScanNet++ | MapFree | 75.2 | 75.2 | 74.6 | 76.5 | 74.5 |
| SegMASt3R (SPP + Dustbin MF) | ScanNet++ | MapFree | 88.7 | 88.6 | 88.6 | 88.5 | 93.9 |
| SegMASt3R (MF) | MapFree | MapFree | 93.7 | 93.3 | 93.7 | 93.9 | 93.9 |
Evaluated with pseudo-GT masks from SAM2 propagation. Adding a dustbin parameter already improves indoor→outdoor transfer, while direct training on MapFree gives the best performance across all pose bins.
Reference image pairs and SegMASt3R matches demonstrating robustness to 180° viewpoint changes and perceptual aliasing. Colors indicate matched segments; correct matches are contiguous across views.
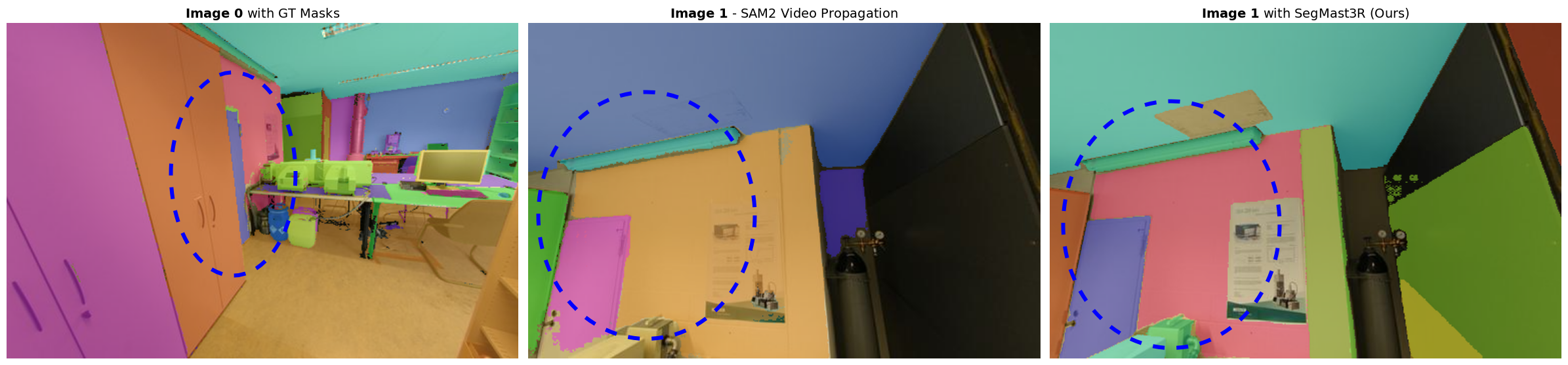
Below are several examples comparing SAM2 two-frame propagation vs SegMASt3R under extreme viewpoint changes. Each row shows: (1) reference / query image, (2) SAM2 matches, (3) SegMASt3R matches. Notice cases of instance aliasing (multiple similar objects) where SAM2 fails while SegMASt3R correctly associates.





Watch SegMASt3R guiding RoboHop on HM3D episodes — left half is vanilla RoboHop which is using SuperPoint + LightGlue matcher; right half is with SegMASt3R as the matcher.
nav_bed_20 — Success vs Failure (SegMASt3R succeeds)
nav_chair_8 — Fewer steps & stable localization
nav_chair_55 — Success vs Failure (SegMASt3R succeeds)
nav_sofa_9 — Fewer steps and stable behavior
Short guidance: top of each video shows overhead / map view; middle shows segment visualization; bottom shows egocentric RGB. Videos illustrate improved success and fewer steps when using SegMASt3R.
| Method | office0 | office1 | office2 | office3 | office4 | room0 | room1 | room2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | AP@50 | AP | AP@50 | AP | AP@50 | AP | AP@50 | AP | AP@50 | AP | AP@50 | AP | AP@50 | AP | AP@50 | |
| ConceptGraphs (MobileSAM masks) | 11.84 | 28.43 | 20.31 | 43.79 | 8.63 | 22.82 | 8.07 | 22.83 | 9.46 | 24.73 | 12.23 | 34.34 | 5.83 | 12.96 | 7.83 | 23.82 |
| ConceptGraphs (GT masks) | 43.53 | 69.68 | 22.48 | 40.71 | 43.46 | 60.69 | 32.06 | 53.44 | 39.63 | 68.22 | 44.89 | 69.64 | 17.96 | 36.53 | 25.93 | 43.63 |
| SegMASt3R (Ours, GT masks) | 79.93 | 87.17 | 54.89 | 64.42 | 64.00 | 85.50 | 58.02 | 79.93 | 67.48 | 85.01 | 71.02 | 91.22 | 64.09 | 85.50 | 56.35 | 76.66 |
Key takeaways:
Qualitative: each column shows (left) ground-truth RGB, (middle) ConceptGraphs mapping (MobileSAM masks), (right) SegMASt3R mapping. Colors = object instances. Observe reduced over-segmentation and better consistent identities with SegMASt3R.

Ground Truth RGB

ConceptGraphs Baseline

SegMASt3R Enhanced
| Method | Ss=16, Sρ=0.25 | Ss=16, Sρ=0.5 | Ss=32, Sρ=0.25 | Ss=32, Sρ=0.5 | ||||
|---|---|---|---|---|---|---|---|---|
| SPL | SSPL | SPL | SSPL | SPL | SSPL | SPL | SSPL | |
| RoboHop (SuperPoint + LightGlue matcher) | 36.34 | 54.25 | 54.51 | 69.98 | 60.57 | 68.29 | 57.52 | 68.47 |
| RoboHop + SegMASt3R | 63.60 | 78.84 | 63.60 | 78.33 | 66.62 | 75.20 | 63.56 | 73.89 |

RoboHop Baseline

SegMASt3R Enhanced
Navigation Improvements:
@article{Jayanti2025SegMASt3R,
author = {Rohit Jayanti and
Swayam Agrawal and
Vansh Garg and
Siddharth Tourani and
Muhammad Haris Khan and
Sourav Garg and
Madhava Krishna},
title = {SegMASt3R: Geometry Grounded Segment Matching},
booktitle = {Advances in Neural Information Processing Systems},
year = {2025},
volume = {38},
url = {https://neurips.cc/virtual/2025/loc/san-diego/poster/119228},
}